Flow Matching Lecture 2
Published:
Flow Matching
接下来, 我们要做的事情是拿我们手上的数据
\[z_1,\dots,z_N \sim p_{data}\]去训练我们的 VF $u_t^{\theta}$. 按照 DL 一般任务(分类或回归等)的思路, 我们可能会想着通过定义损失函数
\[\mathcal{L}(u_t^{\theta}, u_t^{gt})\]然后把数据扔进去通过反向传播算法优化参数 $\theta$ 的方式去训练模型. 可惜目前我们手上只有 $p_{data}$ 中采样的样本, 却并不知道 $u_t^{gt}$ 该如何得到. 这是我们接下来需要解决的问题, 即通过 $z_i$ 构造那个可以被训练的目标.
Important:
-
所有困难的证明都被跳过了, 并且通过上标标出, 这一部分证明细节不影响整个 Flow Matching 流程的理解. 或许之后我会用另一个 note 补充这些细节.
-
尽管需要复杂的数学证明被跳过了, 仍需要基本的概率论和微积分知识理解整个笔记.
-
需要仔细区分哪些内容是设计上的选择, 哪些是数学上的必然(尽管我们在这个 note 省略了其证明).
这节 lecture 主要会涉及以下三对 (六个) 概念.
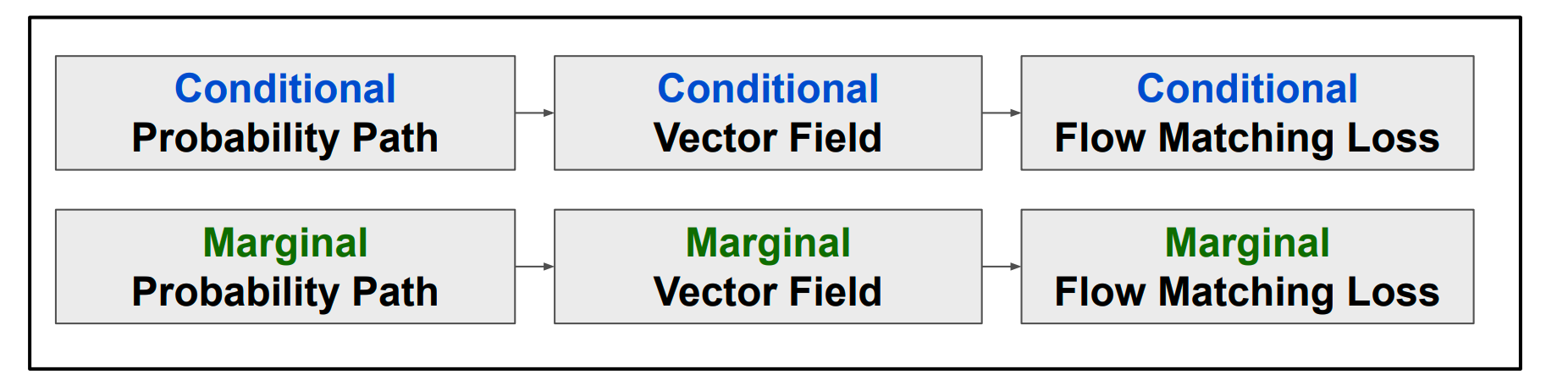
这里的 Condition 统一指我们 $p_{data}$ 中的某个数据点 $z$; 而 $x$ 是 Marginal Probability Path 中的随机变量, 是 Marginal VF 中运动的点, 是最终我们需要计算 Marginal Flow Matching Loss 的变量. 区分两者是理解一切的关键.
1 Probability Paths
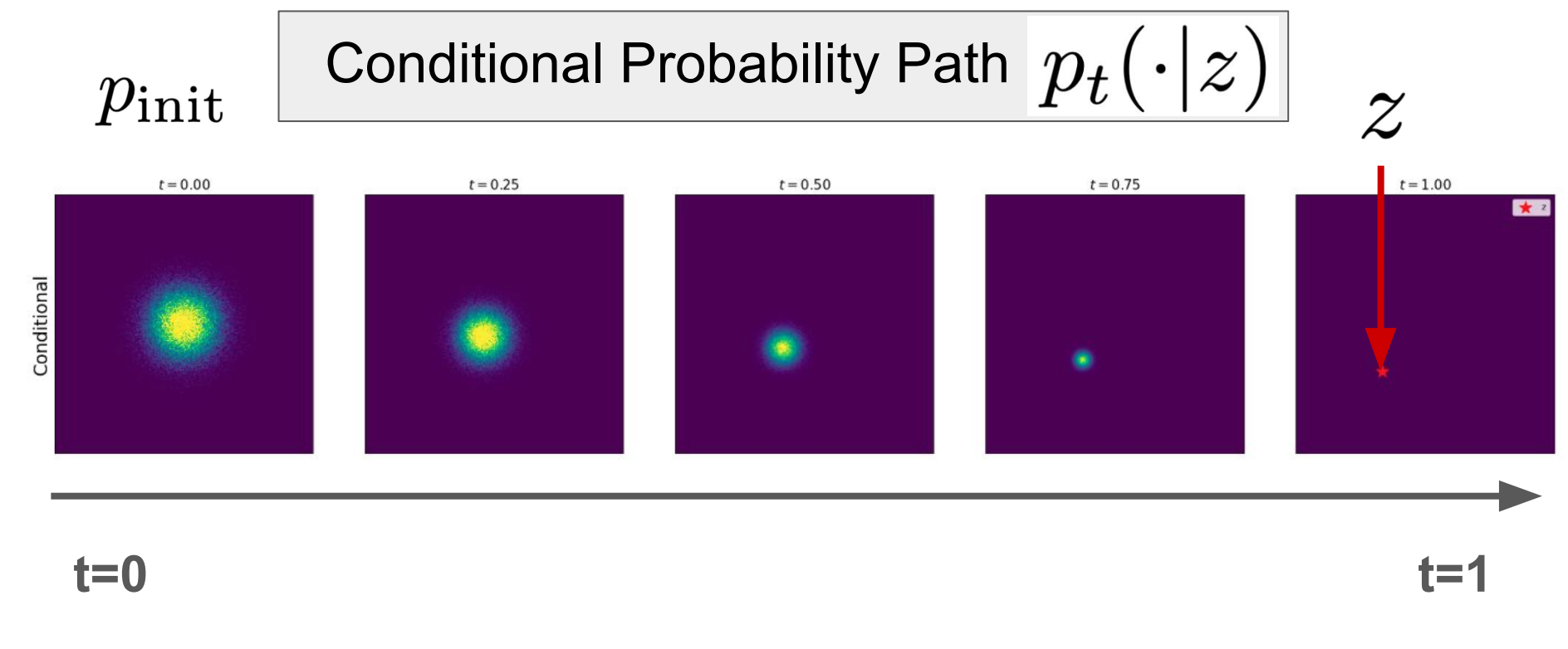
我们的 Probability Paths 定义为 $p_t(\cdot \mid z)$, 满足
\[p_1(\cdot \mid z)=\delta_z,\,\, p_0(\cdot \mid z)=p_{init}\]其中 $p_1(\cdot \mid z)$ 是狄利克雷分布.
Note:
狄利克雷分布记作 $\delta_z$, $X\sim \delta_z$ 意味着任意一次采样, $X=z$ 永远成立.
Note:
- Probability Path 指的是一个随时间连续变化的概率密度函数族.
- Conditional Probability Path 中的 Condition 是一个 $p_{data}$ 中 sample 的数据点.
- $\delta_z$ 是一个每次采样只能采样出 $z$ 的分布.
- $p_t(\cdot \mid z)$ 是在 $p_0$ 和 $p_1$ 之间的平滑插值.
我们可以==选择==构建 Gaussian conditional probability path:
\[p_t(\cdot \mid z) = \mathcal{N}(\alpha_t z, \beta^2_t I_d)\]Note:
- (4) 来自设计上的选取而非数学上的必然, 我们选择 (4) 是因为其满足 (3) , 并且性质很好, 形式简单 (最后能看到这能帮助我们得到一个简洁的 loss).
我们将 $\alpha$ 和 $\beta$ 视作某种 noise schedulers. 为满足 (3) , 这里需要满足
\[\alpha_0 = 0, \beta_0 = 1\\ \alpha_1 = 1, \beta_1 = 0\]除此之外, $\alpha_t$ 和 $\beta_t$ 应该 “光滑”. 在满足这些要求的情况下, $\alpha_t$ 和 $\beta_t$ 可以自由选取.
比如, 我们可以取
\[\alpha_t =t; \,\, \beta_t = 1-t\\ \alpha_t =\sin{\frac{\pi t}{2}}; \,\, \beta_t = \cos{\frac{\pi t}{2}}\\ \alpha_t =\sqrt t; \,\, \beta_t = \sqrt{1-t}\\ ...\]接下来我们推导 Marginal Probability Path, 这需要借助全概率公式
Note:
全概率公式
设 $B_1, B_2, \dots, B_n$ 是样本空间 $\Omega$ 的一个划分(即它们两两互不相交,且它们的并集是整个样本空间,每个 $B_i$ 的概率都大于 0)。
对于任意事件 $A$,全概率公式的形式为:
\[P(A) = \sum_{i=1}^{n} P(B_i)P(A \mid B_i)\]如果是连续型随机变量的形式,求和符号 $\sum$ 会变成积分符号 $\int$:
\[P(A) = \int_{-\infty}^{+\infty} P(A \mid B=y)f_Y(y)dy\]基于全概率公式, 可以直接写出
\[p_t(x) = \int_{\mathbb{R}^d} p_t(x \mid z)p_{data}(z)dz\](9) 是一个定积分, 但是积分区域 $\mathbb{R}^d$ 因为是这个域, 所以往往省略.
可以推导出
\[p_0(t)=p_{init}\\ p_1(t)=p_{data}\]这个推导过程繁琐但显然, 直观上这件事也比较好理解.
从而, 我们借助基于单个数据点定义的 Conditional Probability Path 构建了一个从 $p_{init}$ 到 $p_{data }$ 的 Probability Path:
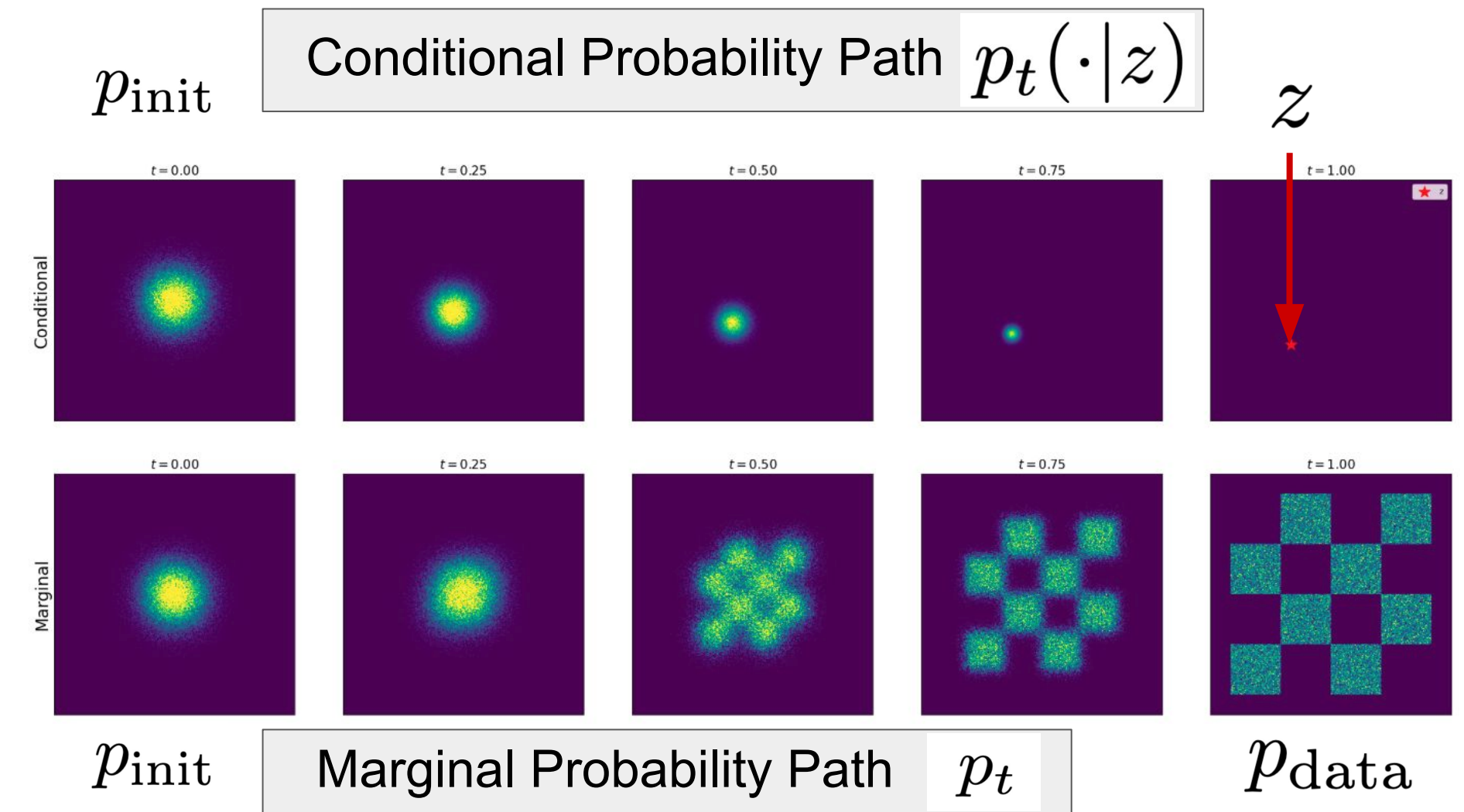
2 Vector Field
对于每个 Conditional Probability Path, 都存在一个等效的 ODE ^[1]^.
\[X_0\sim p_0(\cdot \mid z), \frac{d}{dt} X_t = u_t(X_t \mid z) \,\, \Rightarrow \,\, X_t\sim p_t(\cdot \mid z)\]其中, $p_0(\cdot \mid z)$ 就是 $p_{init}$ 这个式子在说, 我们可以从 $p_{init}$ 中采样, 然后沿着 VF 演化到 $t$ 时刻 (比如用 Euler method), 其等效于从 $p_t(\cdot \mid z)$ 中采样.
在 (4) 的情形下, 这个 VF 形式非常简单 ^[2]^:
\[u_t(x \mid z)=\big( \dot \alpha_t - \frac{\dot \beta_t}{\beta_t}\alpha_t \big) z + \frac{\dot \beta_t}{\beta_t} x\]好, 我们现在有了 Conditional Vector Field, 可以去构造 Marginal Vector Field.
现在, 我们想要找到一个 “Marginal VF”, 满足
\[X_0\sim p_{init}, \frac{d}{dt}X_t = u_t(X_t) \,\, \Rightarrow X_t\sim p_t(0\le t\le 1)\]Note:
- 我们称其为 “Marginal” 的, 因为就像 Conditional PDF 到 Marginal PDF 一样, 我们去掉了条件 $z$
- 我们想要得到这个, 是因为这个就是我们从最初想要做到的: 通过一个 VF, 将 $p_{init}$ 转换为 $p_{data}$. 一旦我们得到这样的 VF, 从复杂分布 $p_{data}$ 采样的任务就转变成了从简单分布 $p_{init}$ 采样并且沿着 VF 演化.
- VF (最终被 neural network 建模) 数学上不提供任何随机性, 所有随机性均来源于从 $p_{init}$ 的那次采样.
这样的 $u_t(x)$ 是存在的, 可以证明 ^[3]^
\[u_t(x) = \int u_t(x \mid z)\frac{p_t(x \mid z)p_{data}(z)}{p_t(x)}dz\]满足 (13) 的要求.
3 Loss Function
一个自然的想法是用 $u_t$ 的 squared error 作为 loss, 也就是说我们将 flow matching loss 定义为
\[\mathcal {L}_{FM} = \mathbb{E}_{t\sim \mathcal{U}(0,1),\, z\sim p_{data}, \,\, x\sim p_t(\cdot \mid z)}[||\hat u_t^\theta(x) - u_t(x) ||^2]\]Note:
我们用 $\hat {}$ 标记 $\hat{u}_t^\theta(x)$ 是网络预测的 VF, 并且增添上标 $^\theta$ 强调其依赖于网络参数 $\theta$, $u_t(x)$ 则是真实的 VF
不过, 这个损失是不可计算的, 因为其依赖 $u_t(x)$, 而计算 $u_t(x)$ 需要根据 (14) 式, 这个式子带有 $p_{data}$, 这个 $p_{data}$ 本来就是我们要求的未知分布. 幸运的是, 可以证明 ^[4]^ , 最小化 flow matching loss 等价于最小化以下 conditional flow matching loss
\[\mathcal {L}_{CFM} = \mathbb{E}_{t\sim \mathcal{U}(0,1),\, z\sim p_{data}, \,\, x\sim p_t(\cdot \mid z)}[||\hat u_t^\theta(x) - u_t(x \mid z) ||^2]\]我们终于可以将之前做的所有不明所以的事情都用起来了, 这里我不省略剩下的推导:
将 (4) 和 (12) 代入 (16):
\[\mathcal {L}_{CFM} = \mathbb{E}_{t\sim \mathcal{U}(0,1),\, z\sim p_{data}, \,\, x\sim \mathcal{N}(\alpha_tz,\beta_t^2I_d) }\Big[||\hat u_t^\theta(x) - \big( \dot \alpha_t - \frac{\dot \beta_t}{\beta_t}\alpha_t \big) z - \frac{\dot \beta_t}{\beta_t} x ||^2\Big]\]运用重参数化的技术, 采样 $x\sim\mathcal{N}(\alpha_tz,\beta_t^2I_d)$ 等价于采样 $\epsilon\sim \mathcal{N}(0,I_d)$, 然后设 $x = \alpha_t z +\beta_t \epsilon$
\[\begin{aligned} \mathcal{L}_{\text{CFM}} &= \mathbb{E}_{t \sim \mathcal{U}(0,1), \, z \sim p_{\text{data}}, \, \epsilon \sim \mathcal{N}(0, I_d)} \left[ \left\| \hat{u}^\theta_t(\alpha_t z + \beta_t \epsilon) - \left( \dot{\alpha}_t - \frac{\dot{\beta}_t}{\beta_t} \alpha_t \right) z - \frac{\dot{\beta}_t}{\beta_t}(\alpha_t z + \beta_t \epsilon) \right\|^2 \right] \\ &= \mathbb{E}_{t \sim \mathcal{U}(0,1), \, z \sim p_{\text{data}}, \, \epsilon \sim \mathcal{N}(0, I_d)} \left[ \left\| \hat{u}^\theta_t(\alpha_t z + \beta_t \epsilon) - \dot{\alpha}_t z + \frac{\dot{\beta}_t}{\beta_t}\alpha_t z - \frac{\dot{\beta}_t}{\beta_t}\alpha_t z - \dot{\beta}_t \epsilon \right\|^2 \right] \\ &= \mathbb{E}_{t \sim \mathcal{U}(0,1), \, z \sim p_{\text{data}}, \, \epsilon \sim \mathcal{N}(0, I_d)} \left[ \left\| \hat{u}^\theta_t(\alpha_t z + \beta_t \epsilon) - (\dot{\alpha}_t z + \dot{\beta}_t \epsilon) \right\|^2 \right] \end{aligned}\]当我们取 $\alpha_t=t, \beta_t =1-t$ 时 (这个叫 Optimal transport), (18) 变成了
\[\mathcal{L}_{CFM} = \mathbb{E}_{t \sim \mathcal{U}(0,1), \, z \sim p_{\text{data}}, \, \epsilon \sim \mathcal{N}(0, I_d)} \left[ \left\| \hat{u}^\theta_t\big(tz + (1-t) \epsilon\big) - (z - \epsilon) \right\|^2 \right]\]Note:
- 这里的 $tz+(1-t)\epsilon$ 对应于 $x = tz + (1-t) \epsilon$
- 这里的 $z-\epsilon$ 对应于 $u_t(x \mid z)$
至此, 我们终于得到了我们的训练目标. 整个 loss 计算可以通过以下流程做到:
Important:
- 采样一个数据点 $z\sim p_{data}$
- 采样一个时刻 $t\sim \mathcal{U}(0,1)$
- 采样一个高斯噪声 $\epsilon\sim \mathcal{N}(0,I_d)$
- 为数据点 “加噪” $x = tz + (1-t)\epsilon$
- 计算网络的输出 $\hat u ^\theta _t(x)$
- 与 $z-\epsilon$ 之间计算平方平方误差